ConcurrentHashMap介绍
因为ConcurrentHashMap支持并发操作,所以源码理解起来并不是很容易,尤其是JDK1.8的源码加入红黑树,本文分别分析JDK1.8和JDK1.7源码
JDK1.8 中 ConcurrentHashMap 类取消了 Segment 分段锁,采用 CAS + synchronized 来保证并发安全,数据结构跟 jdk1.8 中 HashMap 结构类似,都是数组 + 链表(当链表长度大于8时,链表结构转为红黑二叉树)结构。
ConcurrentHashMap 中 synchronized 只锁定当前链表头节点或红黑二叉树的根节点,只要节点 hash 不冲突,就不会产生并发,相比 JDK1.7 的 ConcurrentHashMap 效率又提升了 N 倍!
重要属性
//默认为0
//当初始化时为-1
//当扩容时为-(1+扩容线程数)
//当初始化或扩容完成后,为下一次扩容阈值大小
private transient volatile int sizeCtl;
//扩容如果某个bin迁移完毕,用ForwardingNode作为旧table bin的头节点
//如果扩容时遇到get请求,发现头节点是ForwardingNode,则需要去新table中查找
static final class ForwardingNode<K,V> extends Node<K,V>
Node节点类: 和HashMap中的节点类似,只是其val变量和next指针都用volatile来修饰。且不允许调用setValue方法修改Node的value值。这个类是后面三个类的基类。
TreeNode: 树节点类,当链表长度过长的时候,会转换为TreeNode。但是与HashMap不相同的是,它并不是直接转换为红黑树,而是把这些结点包装成TreeNode放在TreeBin对象中,由TreeBin完成对红黑树的包装。而且TreeNode在ConcurrentHashMap继承自Node类,而并非HashMap中的继承自LinkedHashMap.Entry<K,V>类,也就是说TreeNode带有next指针,这样做的目的是方便基于TreeBin的访问。
TreeBin: 头节点,这个类并不负责包装用户的key、value信息,而是直接放了一个名为root的TreeNode节点,这个是他所包装的红黑树的根节点,也就是说在实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象,这是与HashMap的区别。另外这个类还带有了读写锁。HashMap桶中存储的是TreeNode结点,这里的根本原因是==并发过程中,有可能因为红黑树的调整,树的形状会发生变化,这样的话,桶中的第一个元素就变了,而使用TreeBin包装的话,就不会出现这种情况。 这种类型的节点, hash值为-2,从下面的构造函数中就可以看出来。这样我们通过hash值是否等于-2就可以判断桶中的节点是否是红黑树。

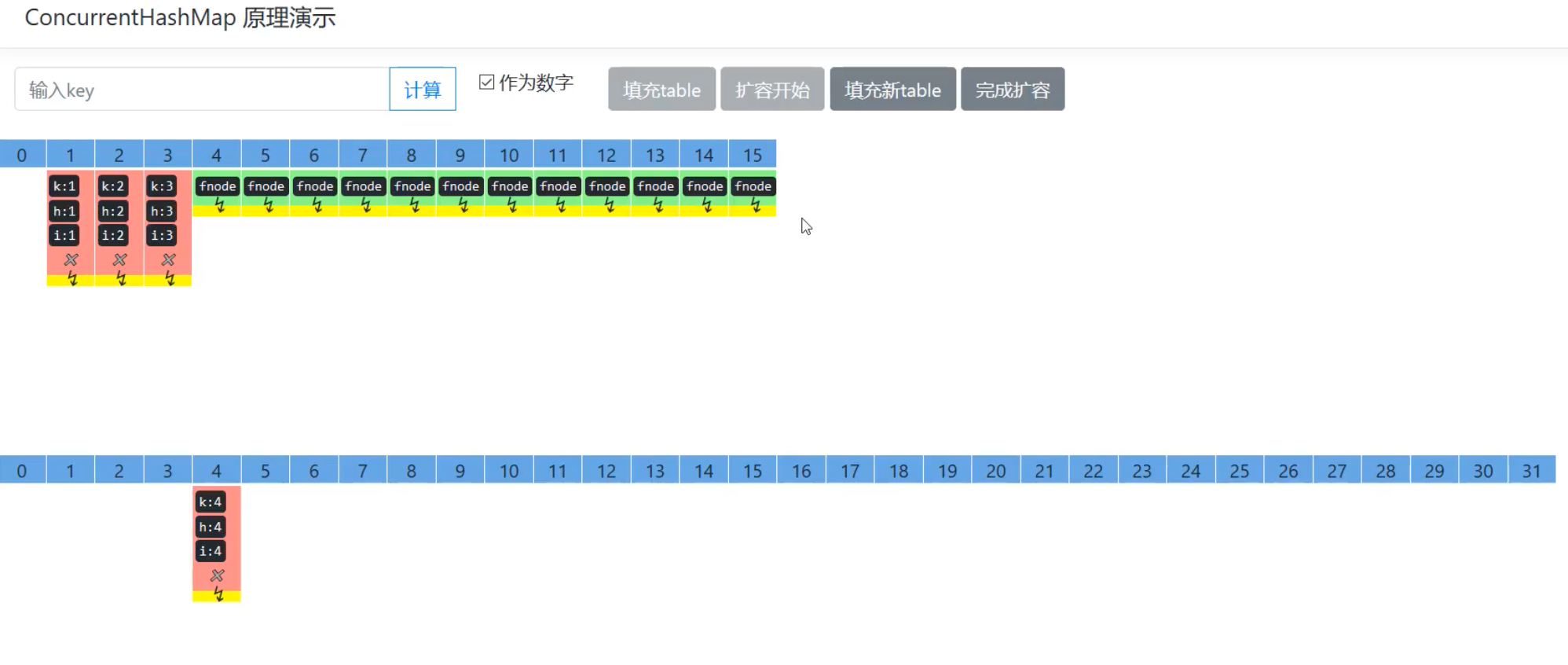{kind=link}
构造方法
实现的懒加载,在构造方法中仅仅计算了table的大小,
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
//tableSizeFor仍然是保证了计算的大小是2的N次方,即16,32,64
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
JDK1.7中的ConcurrentHashMap:
ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
其示意图如下(图片来源于网络):
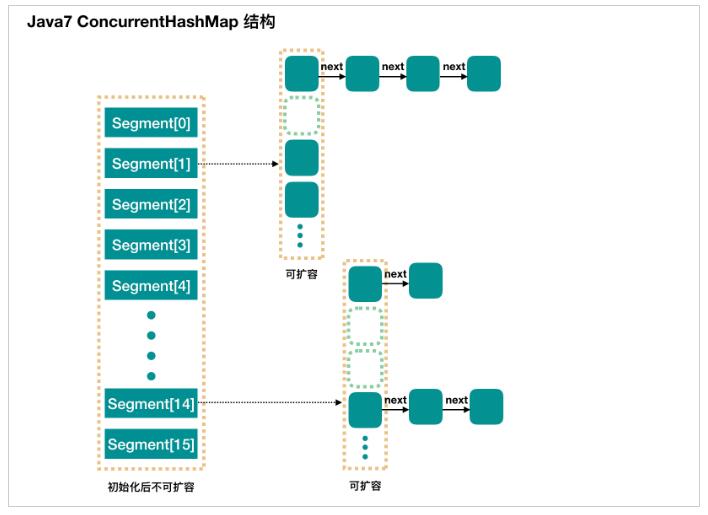
ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
具体到每个 Segment 内部,其实每个 Segment 很像HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
JDK1.8中的ConcurrentHashMap:
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
其示意图如下(图片来源于网络):
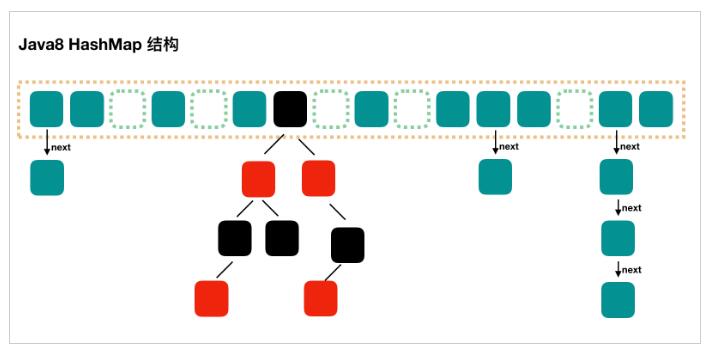
结构上和 Java8 的 HashMap 基本上一样,不过它要保证线程安全性,所以在源码上确实要复杂一些。
ConcurrentHashMap源码分析
JDK1.7源码分析
概念
Segment: 可重入锁,继承ReentrantLock 也称之为桶或者槽,ConcurrentHashMap包含一个Segment数组,每个Segment包含一个HashEntry数组,当修改HashEntry数组采用开链法处理冲突,所以它的每个HashEntry元素又是链表结构的元素。
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
concurrencyLevel:并发数,并行级别,Segment数,默认为16
HashEntry:主要存储键值对 可以叫节点,源码如下:
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
构造函数
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 计算并行级别 ssize,因为要保持并行级别是 2 的 n 次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// segmentShift(段偏移量)和segmentMask(段掩码)在定位segment使用
// 我们这里先不要那么烧脑,用默认值,concurrencyLevel 为 16,sshift 为 4
// 那么计算出 segmentShift 为 28,segmentMask 为 15,后面会用到这两个值
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是设置整个 map 初始的大小,
// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小
// 如 initialCapacity 为 64,那么每个 Segment 或称之为"槽"可以分到 4 个
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// 默认 MIN_SEGMENT_TABLE_CAPACITY 是 2,这个值也是有讲究的,因为这样的话,对于具体的槽上,
// 插入一个元素不至于扩容,插入第二个的时候才会扩容
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 创建 Segment 数组,
// 并创建数组的第一个元素 segment[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 往数组写入 segment[0]
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
其他构造函数基本上都会调用该方法进行初始化,只是初始化值不一样,如无参构造,源码如下:
/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
无参构造初始化完成后:
- Segment 数组长度为 16,不可以扩容
- Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容
- 这里初始化了 segment[0],其他位置还是 null
- 当前 segmentShift 的值为 32 - 4 = 28,segmentMask 为 16 - 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
put过程分析
我们先看 put 的主流程,这个put不难,主要是return中put方法使用
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 1. 计算 key 的 hash 值
int hash = hash(key);
// 2. 根据 hash 值找到 Segment 数组中的位置 j
// hash 是 32 位,无符号右移 segmentShift(28) 位,剩下低 4 位,
// 然后和 segmentMask(15) 做一次与操作,也就是说 j 是 hash 值的最后 4 位,也就是槽的数组下标
int j = (hash >>> segmentShift) & segmentMask;
// 刚刚说了,初始化的时候初始化了 segment[0],但是其他位置还是 null,
// ensureSegment(j) 对 segment[j] 进行初始化
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// 3. 插入新值到对应的槽中
return s.put(key, hash, value, false);
}
下面就是Segment中的put操作了,Segment内部由数组+链表组成,源码如下(接上面):
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//这里有个tryLock(),在往该segment里面写入数据前,需先获得该segment的独占锁
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 每一个segment对应一个HashEntry数组
HashEntry<K,V>[] tab = table;
//利用 hash 值,求应该放置的数组下标
//每个segment中数组的长度都是2的N次方,所以这里经过运算之后,取的是hash的低几位数据
int index = (tab.length - 1) & hash;
// 定位到HashEntry数组中的某个结点
//first 是数组该位置处的链表的表头
HashEntry<K,V> first = entryAt(tab, index);
//遍历链表
//该位置没有任何元素和已经存在一个链表的这两种情况
for (HashEntry<K,V> e = first;;) {
//链表不为空
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
//覆盖旧值
e.value = value;
++modCount;
}
break;
}
//继续顺着链表走
e = e.next;
}
else {// 如果链表为空(表头为空)
//node不为null,直接设置为链表表头
if (node != null)
node.setNext(first);
else
//如果为null,根据key value 创建结点并插入链表
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//判断是否需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
//不需要扩容,将node放到数组中的对应位置
//其实就是将新的节点设置成原链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//解锁
unlock();
}
//返回旧值
return oldValue;
}
整体流程还是比较简单的,大概有如下几步:
- 调用tryLock尝试加锁,如果加锁成功,则node为null,否则scanAndLockForPut自旋等待并且寻找对应key的节点是否存在
- 获取到锁后,找到对应的HashEntry first, 向后遍历寻找是否有和要找的key equals的HashEntry。
- 如果找到了,则按照是否是putIfAbsent判断是否替换旧的value值
- 如果没有找到(循环到null),则创建一个节点或使用scanAndLockForPut中创建的节点作为新的头结点,判断是否需要rehash, 并设置到HashEntry数组对应的位置。
- 最后解锁,返回key原来对应的value值。
到这里 put 操作就结束了,接下来,我们说一说其中几步关键的操作。
初始化槽:ensureSegment()方法
这个函数的目的就是找到对应的segment,通过CAS来解决并发问题
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
//ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],
//对于其他槽来说,在插入第一个值的时候进行初始化
//这里就需要考虑并发
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 这里看到为什么之前要初始化 segment[0] 了,
// 使用当前 segment[0] 处的数组长度和负载因子来初始化 segment[k]
// 为什么要用“当前”,因为 segment[0] 可能早就扩容过了
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用 while 循环,内部用 CAS,当前线程成功设值或其他线程成功设值后,退出
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
获取写入锁:scanAndLockForPut()
在Segment中put时,首先会调用
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
也就是先通过tryLock()快速获取该segment的独占锁,如果获取失败,在通过scanAndLockForPut()方法来获取锁,
scanAndLockForPut中的处理为不断尝试获取锁的过程中遍历链表,如果最终没有找到和key equals的HashEntry则创建一个HashEntry并在获取到锁后返回它,如果自旋超过一定次数则使用lock进行加锁等待。
其源码如下:
/**
* Scans for a node containing given key while trying to
* acquire lock, creating and returning one if not found. Upon
* return, guarantees that lock is held. UNlike in most
* methods, calls to method equals are not screened: Since
* traversal speed doesn't matter, we might as well help warm
* up the associated code and accesses as well.
*
* @return a new node if key not found, else null
*/
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
//循环获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
//重试次数如果超过MAX_SCAN_RETRIES(单核1多核64),那么不抢了,进入到阻塞队列等待锁
//lock() 是阻塞方法,直到获取锁后返回
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
// 那就是有新的元素进到了链表,成为了新的表头
//所以这边的策略是,相当于重新走一遍这个 scanAndLockForPut 方法
else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
这个方法有两个出口,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
方法过程大概如下:
- entryForHash进行一次volatile读, 然后在循环中尝试tryLock
- tryLock不成功的情况下,如遍历链表,有一个retries变量初始时为-1, 当遍历到最后一个节点时还没有找到则创建一个HashEntry并且将retries置为0,如果找到了对应的key的Entry也将retries置为0。
- MAX_SCAN_RETRIES在类初始化时根据系统的CPU处理器的数量决定,如果CPU大于1则是64,否则是1。
- 创建好HashEntry或已经匹配到HashEntry后则进入下一个else if,其中++retries判断如果大于MAX_SCAN_RETRIES就是用lock()方法中断当前的spin lock。
- 如果不大于MAX_SCAN_RETRIES, 则判断retryies是否为奇数,这个其实是给单处理应用的,并且判断当前的HashEntry的头节点是否和循环开始时的相等,如果不相等说明有其他线程进行了修改,需要重新遍历链表。这里的 (retries & 1) 确认容易让人不解,因为多处理器时64的话retries也会出现2这种偶数的可能,但是最终加锁后还是会进行重新读取HashEntry链表的,所以这里如果有读取到stale数据最终是能够发现的。那这个方法的意义在于什么呢?首先通过读取HashEntry帮助将对应的数据加载到CPU缓存行中并且帮助出发JIT编译来加热代码,其次如果创建了HashEntry并且最终却是没有对应的key的话节省了创建HashEntry的时间,这两个用途都能够减少之后加锁的时间。Doug lea对(reties &1)这个用法也进行了回复http://altair.cs.oswego.edu/pipermail/concurrency-interest/2014-August/012881.html
扩容: rehash
这里的扩容是 segment 数组某个位置内部的数组 HashEntry[] 进行扩容,扩容后,容量为原来的 2 倍
segment 数组不能扩容,源码如下:
/**
* Doubles size of table and repacks entries, also adding the
* given node to new table
*/
@SuppressWarnings("unchecked")
private void rehash(HashEntry<K,V> node) {
/*
* Reclassify nodes in each list to new table. Because we
* are using power-of-two expansion, the elements from
* each bin must either stay at same index, or move with a
* power of two offset. We eliminate unnecessary node
* creation by catching cases where old nodes can be
* reused because their next fields won't change.
* Statistically, at the default threshold, only about
* one-sixth of them need cloning when a table
* doubles. The nodes they replace will be garbage
* collectable as soon as they are no longer referenced by
* any reader thread that may be in the midst of
* concurrently traversing table. Entry accesses use plain
* array indexing because they are followed by volatile
* table write.
*/
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
//扩容一倍
int newCapacity = oldCapacity << 1;
//计算新的阀值
threshold = (int)(newCapacity * loadFactor);
//创建新的数组
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
//新的掩码
int sizeMask = newCapacity - 1;
//遍历到的数组,将原数组位置 i 处的链表拆分到 新数组位置 i 和 i+oldCap 两个位置
for (int i = 0; i < oldCapacity ; i++) {
//对应一个链表的表头节点e
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
//计算e对应的这条链表在新数组中对应的下标
//假设原数组长度为 16,e在 oldTable[3] 处,那么 idx 只可能是 3 或者是 3 + 16 = 19
int idx = e.hash & sizeMask;
//只有一个节点时直接放入
if (next == null) // Single node on list
newTable[idx] = e;
else { //链表有多个节点 //Reuse consecutive sequence at same slot
//链表的表头结点做为新链表的尾结点
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
//下面这个 for 循环会找到一个 lastRun 节点,
//这个节点之后的所有元素是将要放到一起的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
//旧数组中一个链表中的数据并不一定在新数组中属于同一个链表,所以这里需要每次都重新计算
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
//lastRun(和之后的元素)插入数组中
newTable[lastIdx] = lastRun;
// Clone remaining nodes
//下面的操作是处理 lastRun 之前的节点,
//这些节点可能分配在另一个链表中,也可能分配到上面的那个链表中
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
//拼接链表
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
//将新来的 node 放到新数组中刚刚的 两个链表之一 的 头部
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
这里并不一定遍历所有的链表元素,因为当后面的节点进过运算在新数据中的hash一样的话,只需要把这一组的头结点插入,后面的节点就会被带入其中。
所以,下面的for循环操作的是链表中lastRun节点之前的节点
for (HashEntry<K,V> p = e; p != lastRun; p = p.next)
get过程分析
get过程大概可以分为以下几步:
- 计算hash值
- 找到segment中对应HashEntry链表
- 遍历链表
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
//计算hash值
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//根据hash找到对应的segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
//找到segment内部数组相应位置的链表,遍历
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
计算size
/**
* Returns the number of key-value mappings in this map. If the
* map contains more than <tt>Integer.MAX_VALUE</tt> elements, returns
* <tt>Integer.MAX_VALUE</tt>.
*
* @return the number of key-value mappings in this map
*/
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
//当重试次数等于3次的时候,直接遍历segment并上锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
//遍历segment数组
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
//计算元素总个数
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
//如果前后两次数据一致,则跳出循环
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
//返回元素总个数
return overflow ? Integer.MAX_VALUE : size;
}
contains系统方法
containsKey 判断是否包含key值对应的数据(节点)
/**
* Tests if the specified object is a key in this table.
*
* @param key possible key
* @return <tt>true</tt> if and only if the specified object
* is a key in this table, as determined by the
* <tt>equals</tt> method; <tt>false</tt> otherwise.
* @throws NullPointerException if the specified key is null
*/
@SuppressWarnings("unchecked")
public boolean containsKey(Object key) {
Segment<K,V> s; // same as get() except no need for volatile value read
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//找到对应的segment分组数据
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
//找打对应的链表遍历
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
//判断
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return true;
}
}
return false;
}
containsValue 判断是否包含value值对应的数据
和size()方法有点类似
/**
* Legacy method testing if some key maps into the specified value
* in this table. This method is identical in functionality to
* {@link #containsValue}, and exists solely to ensure
* full compatibility with class {@link java.util.Hashtable},
* which supported this method prior to introduction of the
* Java Collections framework.
* @param value a value to search for
* @return <tt>true</tt> if and only if some key maps to the
* <tt>value</tt> argument in this table as
* determined by the <tt>equals</tt> method;
* <tt>false</tt> otherwise
* @throws NullPointerException if the specified value is null
*/
public boolean contains(Object value) {
return containsValue(value);
}
/**
* Returns <tt>true</tt> if this map maps one or more keys to the
* specified value. Note: This method requires a full internal
* traversal of the hash table, and so is much slower than
* method <tt>containsKey</tt>.
*
* @param value value whose presence in this map is to be tested
* @return <tt>true</tt> if this map maps one or more keys to the
* specified value
* @throws NullPointerException if the specified value is null
*/
public boolean containsValue(Object value) {
// Same idea as size()
if (value == null)
throw new NullPointerException();
final Segment<K,V>[] segments = this.segments;
boolean found = false;
long last = 0;
int retries = -1;
try {
outer: for (;;) {
// 当重试次数等于3次时,直接遍历每个segment并上锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
long hashSum = 0L;
int sum = 0;
// 遍历segment数组
for (int j = 0; j < segments.length; ++j) {
HashEntry<K,V>[] tab;
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null && (tab = seg.table) != null) {
//遍历某个segment对应的HashEntry数组
for (int i = 0 ; i < tab.length; i++) {
HashEntry<K,V> e;
for (e = entryAt(tab, i); e != null; e = e.next) {
V v = e.value;
//若找到了跳出outer循环
if (v != null && value.equals(v)) {
found = true;
break outer;
}
}
}
//记录总的修改次数
sum += seg.modCount;
}
}
//如果前后两次得到的修改次数一致,就表示查找过程中没有其他线程修改元素,跳出循环
if (retries > 0 && sum == last)
break;
//last保存上一次加起来的总修改次数
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return found;
}
JDK1.8源码分析
概述
1.8中采取的是和HashMap中类似的单数组链表策略,并且在链表长度超过一定大小时转换成红黑树。
- 每个数组元素称为为一个bin或bucket,里面存放的是Node。
- Node代表了一个键值对,并通过next指向下一个节点。Node有一些子类,TreeNode是用平衡树组织的节点, ForwardingNode用于在resize的时候放在Node的头结点,只有table发生扩容的时候,ForwardingNode才会发挥作用
- Node<K,V>[] table是内部数据的bin数组, table的大小。
- sizeCtl用于控制table的初始化和resize。
- sizeCtl为负数的时候表示正在进行初始化或者resize, -1表示正在初始化或者扩容, 当table为null的时候存储的是初始时的table的大小或者0表示默认值。所以,如果某个线程想要初始化table或者对table扩容,需要去竞争sizeCtl这个共享变量,获得变量的线程才有许可去进行接下来的操作,没能获得的线程将会一直自旋来尝试获得这个共享变量,所以获得sizeCtl这个变量的线程在完成工作之后需要设置回来,使得其他的线程可以走出自旋进行接下来的操作
- -1 代表table正在初始化
- -N 表示有N-1个线程正在进行扩容操作
- 其余情况:
- (1)如果table未初始化,表示table需要初始化的大小。
- (2)如果table初始化完成,表示table的容量,默认是table大小的0.75倍
- table:默认为null,初始化发生在第一次插入操作,默认大小为16的数组,用来存储Node节点数据,扩容时大小总是2的幂次方。
- nextTable:默认为null,扩容时新生成的数组,其大小为原数组的两倍。
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node<K,V>[] nextTable;
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
/**
* The next table index (plus one) to split while resizing.
*/
private transient volatile int transferIndex;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
*/
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;
// views
private transient KeySetView<K,V> keySet;
private transient ValuesView<K,V> values;
private transient EntrySetView<K,V> entrySet;
构造函数
/**
* Creates a new, empty map with the default initial table size (16).
*/
//无参构造函数
public ConcurrentHashMap() {
}
/**
* Creates a new, empty map with an initial table size
* accommodating the specified number of elements without the need
* to dynamically resize.
*
* @param initialCapacity The implementation performs internal
* sizing to accommodate this many elements.
* @throws IllegalArgumentException if the initial capacity of
* elements is negative
*/
//通过初始容量,计算sizeCtl
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
put过程分析
大致可以分为以下步骤:
- 根据 key 计算出 hash 值;
- 判断是否需要进行初始化;
- 定位到 Node,拿到首节点 f,判断首节点 f:
- 如果为 null ,则通过 CAS 的方式尝试添加;
- 如果为 f.hash = MOVED = -1 ,说明其他线程在扩容,参与一起扩容;
- 如果都不满足 ,说明桶下标有冲突,用synchronized 锁住 f 节点,判断是链表(f.hash >0)还是红黑树(f.hash <0),遍历插入;
- 当在链表长度达到 8 的时候,数组扩容或者将链表转换为红黑树。
源代码如下:
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p>The value can be retrieved by calling the {@code get} method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 和hashmap不一样的是,不允许有null
if (key == null || value == null) throw new NullPointerException();
////计算hash值,两次hash操作,key的hash码是个正整数
int hash = spread(key.hashCode());
int binCount = 0;
//死循环,直到插入成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//table中还没有元素,初始化
if (tab == null || (n = tab.length) == 0)
//初始化数组,里面是用cas保证只有一个线程来创建
tab = initTable();
/*
i=(n-1)&hash 等价于i=hash%n(前提是n为2的幂次方).即取出table中位置的节点用f表示。
有如下两种情况:
1、如果table[i]==null(即该位置的节点为空,没有发生碰撞),则利用CAS操作直接存储在该位置,
如果CAS操作成功则退出死循环。
2、如果table[i]!=null(即该位置已经有其它节点,发生碰撞)
*/
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果数组为空
//用一次 CAS 操作将这个新值放入其中即可
//如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//hash居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
//帮助数据迁移
tab = helpTransfer(tab, f);
else {//到这里就是说,f 是该位置的头结点,而且不为空,有冲突
V oldVal = null;
// 获取链表的头结点的锁
synchronized (f) {
if (tabAt(tab, i) == f) {
//头结点的 hash 值大于 0,说明是链表
if (fh >= 0) {
//用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//binCount != 0 说明上面在做链表操作
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
put方法中有使用到initTable()、helpTransfer()、treeifyBin(),addCount()这几个方法,分别来看看源码:
初始化initTable
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//如果sizeCtl为负数,说明已经有其他线程正在初始化或者初始化完成
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//如果CAS成功,表示正在初始化,将sizeCtl变量设置为-1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//再一次检查确认是否还没有初始化
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将这个数组赋值给 table,table 是 volatile 的
table = tab = nt;
//其实就是0.75*n
sc = n - (n >>> 2);
}
} finally {
//设置sizeCtl的值为sc
sizeCtl = sc;
}
break;
}
}
return tab;
}
sizeCtl默认为0,如果ConcurrentHashMap实例化时有传参数,sizeCtl会是一个2的幂次方的值。所以执行第一次put操作的线程会执行Unsafe.compareAndSwapInt方法修改sizeCtl为-1,有且只有一个线程能够修改成功,其它线程通过Thread.yield()让出CPU时间片等待table初始化完成。
链表转红黑树: treeifyBin
该方法的核心思想是:检查一下table的长度是否大于MIN_TREEIFY_CAPACITY(默认64),如果不大于就调用tryPresize方法将table扩容两倍,就不降链表转化为树了,反之则将table[i]的链表转化为树
/**
* Replaces all linked nodes in bin at given index unless table is
* too small, in which case resizes instead.
*/
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//如果数组长度小于 64 的时候,就两倍扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
//扩容方法,源码见下面分析
tryPresize(n << 1);
//下面的操作就是将链表转换为红黑树
//b是头节点
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
//加锁
synchronized (b) {
if (tabAt(tab, index) == b) {
//下面就是遍历链表,建立一颗红黑树
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
// 将红黑树设置到数组相应位置中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
扩容:tryPresize
/**
* Tries to presize table to accommodate the given number of elements.
*
* @param size number of elements (doesn't need to be perfectly accurate)
*/
//接上面,这里的size传进来的时候就已经翻倍了
private final void tryPresize(int size) {
//如果size大于等于MAXIMUM_CAPACITY的一半,直接扩容到最大值MAXIMUM_CAPACITY,否则调用tableSizeFor方法扩容
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);//tableSizeFor(count)的作用是找到大于等于count的最小的2的幂次方
int sc;
//只有sizeCtl大于等于0才表示该线程可以扩容
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
//没有被初始化,这个if分支和之前的一样
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);//无符号右移2位,即0.75*n
}
} finally {
sizeCtl = sc;//更新扩容阀值
}
}
}
//若欲扩容值不大于原阀值,或现有容量>=最大值,什么都不用做了
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) { // table不为空,且在此期间其他线程未修改table
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 用 CAS 将 sizeCtl 加 1,然后执行 transfer 方法
// 此时 nextTab 不为 null
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//调用 transfer 方法,此时 nextTab 参数为 null
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
/*
Returns the stamp bits for resizing a table of size n.当扩容到n时,调用该函数返回一个标志位
Must be negative when shifted left by RESIZE_STAMP_SHIFT.
numberOfLeadingZeros返回n对应32位二进制数左侧0的个数,如9(1001)返回28
RESIZE_STAMP_BITS=16,
因此返回值为:(参数n的左侧0的个数)|(2^15)
*/
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移:transfer
数据迁移的核心思想就是将一个大的迁移任务分为了一个个任务包,比如原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了。源码中使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。
这个方法需要多花时间去理解,不是很好懂
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16
// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,
// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 如果 nextTab 为 null,先进行一次初始化
// 前面我们说了,外围会保证第一个发起迁移的线程调用此方法时,参数 nextTab 为 null
// 之后参与迁移的线程调用此方法时,nextTab 不会为 null
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
//容量翻倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable 是 ConcurrentHashMap 中的属性
nextTable = nextTab;
// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
// i 是位置索引,bound 是边界,这个循环真的有不好理解,有点懵
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// advance 为 true 表示可以进行下一个位置的迁移了
// 简单理解结局:i 指向了 transferIndex,bound 指向了 transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// 看括号中的代码,nextBound 是这次迁移任务的边界,注意,是从后往前
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// 所有的迁移操作已经完成
nextTable = null;
// 将新的 nextTab 赋值给 table 属性,完成迁移
table = nextTab;
// 重新计算 sizeCtl:n 是原数组长度,所以 sizeCtl 得出的值将是新数组长度的 0.75 倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,
// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 任务结束,方法退出
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,
// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 该位置处是一个 ForwardingNode,代表该位置已经迁移过了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 对数组该位置处的结点加锁,开始处理数组该位置处的迁移工作
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// 头结点的 hash 大于 0,说明是链表的 Node 节点
if (fh >= 0) {
// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,
// 需要将链表一分为二,
// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的
// lastRun 之前的节点需要进行克隆,然后分到两个链表中
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 其中的一个链表放在新数组的位置 i
setTabAt(nextTab, i, ln);
// 另一个链表放在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
// 红黑树的迁移
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果一分为二后,节点数少于 8,那么将红黑树转换回链表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 将ln 放置在新数组的位置 i
setTabAt(nextTab, i, ln);
// 将 hn 放置在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
}
}
}
}
}
addCount()
//check是之前binCount的个数,即链表的长度
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null || //已经有了counterCells,向cell累加
//还没有,向BASECOUNT累加
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//newtable已经创建好,帮忙扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//需要扩容,这时newTable未创建
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
JDK1.8中的get方法
get方法很简单,大概思路如下:
1.首先计算hash值,定位到该table索引位置,如果是首节点符合就返回
2.如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
- 判断table是否为空,如果为空,直接返回null。
- 计算key的hash值,并获取指定table中指定位置的Node节点,通过遍历链表或则树结构找到对应的节点,返回value值。
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//spread方法能确保返回的是正整数
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 判断头结点是否就是我们需要的节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 如果头结点的 hash 小于 0,说明 正在扩容(-1),或者该位置是红黑树(-2)
else if (eh < 0)
// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历链表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
此方法的大部分内容都很简单,只有正好碰到扩容的情况,ForwardingNode.find(int h, Object k) 稍微复杂一些
JDK1.8中size计算流程

{kind=link}
JDK1.8中get方法为什么不需要加锁
get操作可以无锁是由于Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
只能保证提供的原子性读写操作是线程安全的
特别注意的是:ConcurrentHashMap只能保证提供的原子性读写操作是线程安全的
比如有一个场景,一个篮子里面有900个水果,需要装满1000个水果,然后有10个工人把还差的100个水果装进去,ConcurrentHashMap就是这个篮子的本身,可以确保多个工人在装东西进去,不会相互影响干扰,但无法确保工人A看到还需装100个水果但是还未装的时候,工人B就看不到篮子中的水果数量,更值得注意的是,你往这个篮子装 100 个水果的操作不是原子性的,在别人看来可能会有一个瞬间篮子里有964个水果,还需要补36个水果。
先展示错误的代码,如下:
public class ConcurrentHashMapWrongTest implements Runnable{
private static int THREAD_COUNT = 10;
private static int ITEM_COUNT = 1000;
private static final Logger log = LoggerFactory.getLogger(ConcurrentHashMapWrongTest.class);
//用来获得一个指定元素数量模拟数据的ConcurrentHashMap
private ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString(), Function.identity(),
(o1, o2) -> o1, ConcurrentHashMap::new));
}
@SneakyThrows
@Override
public void run() {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
//初始900个元素
log.info("init size:{}", concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//查询还需要补充多少个元素
//synchronized (concurrentHashMap) {
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("threadName : {},gap size:{}", Thread.currentThread().getName(),gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
//}
}));
//等待所有任务完成
forkJoinPool.shutdown();
try {
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
} catch (InterruptedException e) {
e.printStackTrace();
}
//最后元素个数会是1000吗
log.info("threadName : {}, finish size:{} ", Thread.currentThread().getName(),concurrentHashMap.size());
}
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMapWrongTest wrong = new ConcurrentHashMapWrongTest();
Thread[] threads = new Thread[10];
//创建10条线程
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(wrong);
}
//启动10条线程
for (int i = 0; i < 10; i++) {
threads[i].start();
}
for (int i = 0; i < 10; i++) {
threads[i].join();
}
}
}
JDK1.7 与 JDK1.8 中ConcurrentHashMap 的区别?
- 数据结构:取消了 Segment 分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7 采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock 。JDK1.8 采用CAS+synchronized保证线程安全。
- 锁的粒度:JDK1.7 是对需要进行数据操作的 Segment 加锁,JDK1.8 调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位节点的 hash 算法简化会带来弊端,hash 冲突加剧,因此在链表节点数量大于 8(且数据总量大于等于 64)时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从 JDK1.7的遍历链表O(n), JDK1.8 变成遍历红黑树O(logN)
ConcurrentHashMap 的并发度是什么?
并发度可以理解为程序运行时能够同时更新 ConccurentHashMap且不产生锁竞争的最大线程数。在JDK1.7中,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度,默认是16,这个值可以在构造函数中设置。
如果自己设置了并发度,ConcurrentHashMap 会使用大于等于该值的最小的2的幂指数作为实际并发度,也就是比如你设置的值是17,那么实际并发度是32。
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
在JDK1.8中,已经摒弃了Segment的概念,选择了Node数组+链表+红黑树结构,并发度大小依赖于数组的大小。
参考
JDK1.7ConcurrentHashMap源码分析
Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
深入浅出ConcurrentHashMap1.8
《Java源码分析》:ConcurrentHashMap JDK1.8