提到一致性hash算法,首先想到的则是分布式的应用场景,比如说分布式缓存或者数据库分库分表时,不可避免的遇到一个问题:如何将数据均匀的分布到各个节点,并且在加减节点时对数据的影响最小,我们来看看一致性hash算法是否能够解决此问题
一致hash算法
一致hash算法是将所有的哈希值构成一个环,其范围在0 ~ 2^32-1,我们把这个圆环称为hash环,如下图所示:

之后将各个节点散列到这个环上,可以用节点的IP、hostname等具有唯一性字段作为Key进行hash(key),散列之如下:
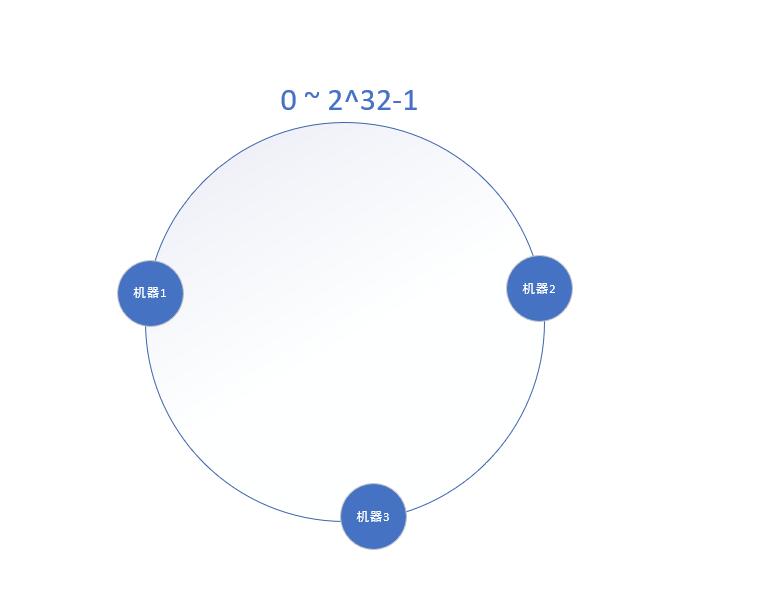
之后再将数据定位到hash环上,同样使用hash算法将key映射到这个环上,在hash环上顺时针查找距离这个数据的hash值最近的机器,即是这个数据所属的机器,散列之后如下图:
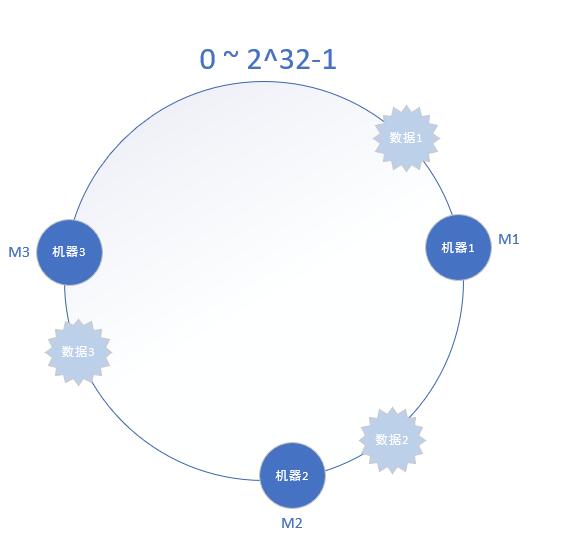
从上图可以看出,数据1顺时针找到最近的机器M1,故机器M1缓存数据1,而机器M2则缓存的是数据2,机器M3缓存的是数据3
容错性
当一个机器宕机了,那此时的hash环就如下图所示:
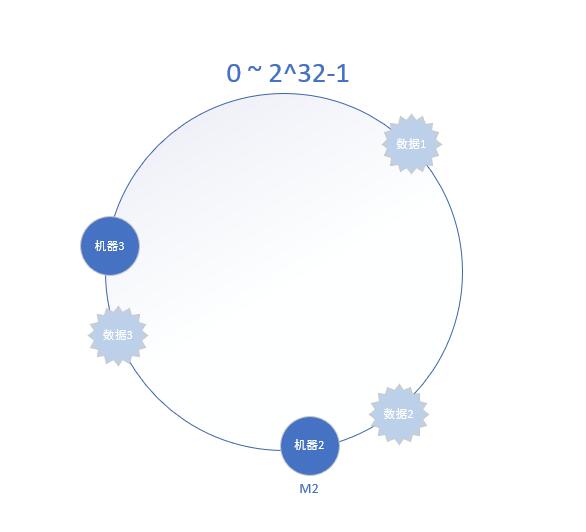
依然根据顺时针方向,数据2和数据3缓存的机器不变,只有数据1重新被映射到机器2上,这样就保证了很好的容错性,只影响很少的一部分数据
拓展性
当新增一台机器时,此时的hash环示意图如下所示:
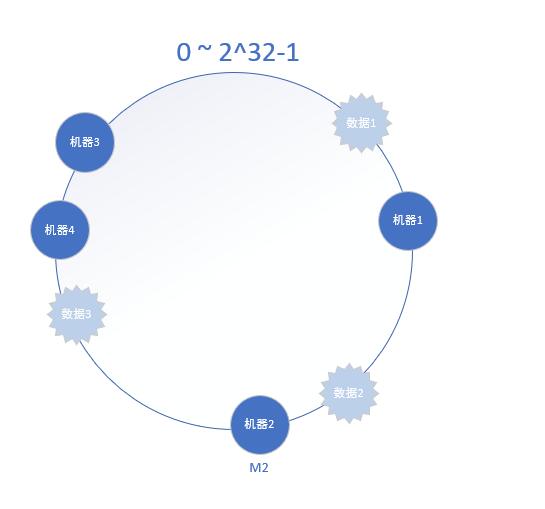
在机器2和机器3之间新增了一个机器4,这时受影响的只有数据3,其他数据无影响
虚拟节点
上面提到的过程基本上就是一致性hash的基本原理了,不过还有一个小小的问题。新加入的机器4只分担了机器3的负载,机器1与机器2的负载并没有因为机器4的加入而减少负载压力。如果4台机器的性能是一样的,那么这种结果并不是我们想要的。 为此,我们引入虚拟节点来解决负载不均衡的问题。
将每台物理机器虚拟为一组虚拟机器,将虚拟机器放置到hash环上,如果需要确定对象的机器,先确定对象的虚拟机器,再由虚拟机器确定物理机器。
说得有点复杂,其实过程也很简单。
还是使用上面的例子,假如开始时存在缓存机器1,机器2,机器3,对于每个缓存机器,都有2个虚拟节点对应,其一致性hash环结构如图所示:
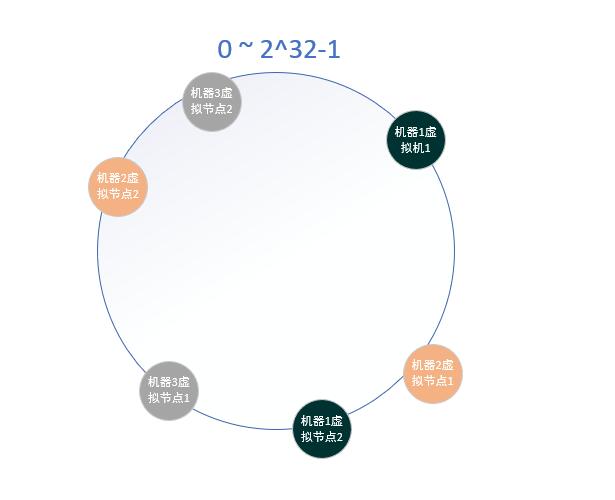
假设有个数据1,其对应的机器1虚拟1节点,对应的缓存机器1,故数据1被分配到机器1中
假设新加入机器4,有两个虚拟节点,对应的虚拟节点为机器4虚拟节点1、机器4虚拟节点2,示意图如下:
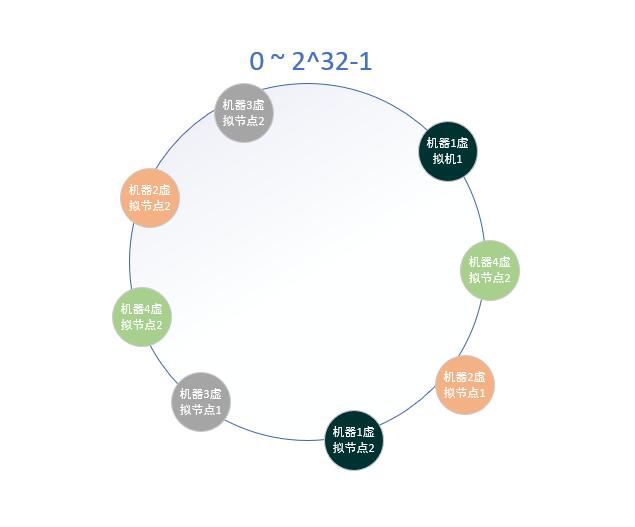
新加入的机器4,影响的虚拟节点有机器2虚拟节点1、机器3虚拟节点2,机器1虚拟机1,即新加入的一台机器,同时影响到原有的3台机器。理想情况下,新加入的机器平等地分担了原有机器的负载,这正是虚拟节点带来的好处。而且新加入机器4后,只影响25%(1/4)对象分配,也就是说,命中率仍然有75%
总结
一致性hash算法解决了分布式环境下机器增加或者减少时,简单的取模运算无法获取较高命中率的问题。通过虚拟节点的使用,一致性hash算法可以均匀分担机器的负载,使得这一算法更具现实的意义。正因如此,一致性hash算法被广泛应用于分布式系统中。
参考